Apache Kafka - Part 1
Prodcuer
- Application that sends the data to the Kafka is called Producer.
- Kafka response Acknowledgment to producer if everything is good.
- Kafka response No Acknowledment to producer if it is not able to read or process the data.
- Producer will retry to send the data to Kafka in following scenario:
- NACK (Not Acknowleged)
- Request Time out
- Many producers can send the data to Kafka concurrently.
Broker
- Kafka is formally called as Cluster of Brokers.
- Brokers receives the data from producers.
- Borkers saves the data
- Temporarly in Page Cache.
- Permanantly on Disk, after OS flush the page cache.
Retension time
- How long the data is stored in the Kafka is determined by Retension Time
- Default retention time is 1 week.
Consumer
- Application that reads the data from the Kafka is called Consumer.
- A consumer periodically polls data from Kafka.
- Many consumers can poll data from Kafka at the same time.
- Different consumers can poll the same data, each at their own pace.
- Parallelism is atained by organizing consumers in a consumer groups and split up the work.
- A consumer pulls message from one or more topics in the cluster.
- A consumer offset keeps track of the last message read and it is stored in a special Kafka topic.
- If necessary the offset can be change to reread the message
Architecture of Kafka
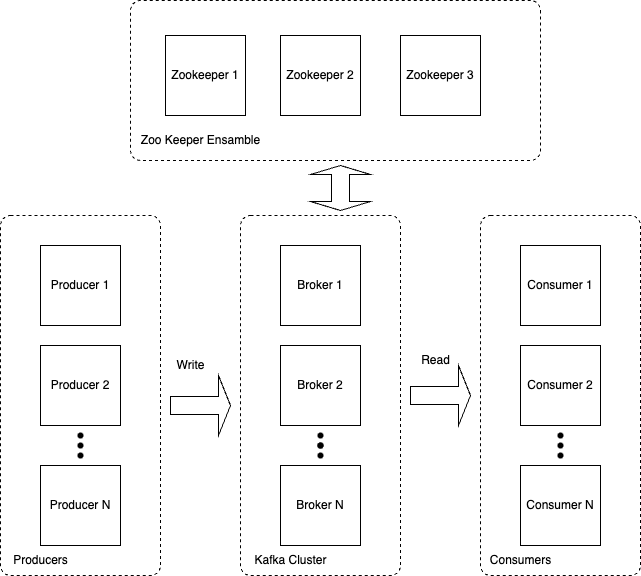
- Producers and consumer are decoupled.
- Add consumer without affecting producer.
- Failure of consumer does not affact system.
- Slow Consumer does not affect producer.
- Producers and Consumers simply need to agree on the data format of the records produced and consumed.
Topics, Partitions, Segments
- Topic A topic comprises all messages of a given category. Example: temperature_reading
- Partitions A topic can be split into many partitions to achieve paralellism and increase throughput.
- A default algorithm used to decide to which partition a message goes uses the Hash Code of the message key.
- A partition can be viewed as log.
- Segment A segment can be pictured as a file on a disk.
- Brokers uses a rolling-file stratergy for creating a new segment.
- Rolling file stratergy is controlled by 2 properties:
- Maximum size of Segment, default is 1 GB.
- Maximum time of Segment, default is 1 week.
- Kafka uses Segments to manage the data retension and remove old data
Note
1. A Topic (category of message) consists of partitions.
2. Partitions of each topic are distributed among the brokers.
3. Each partitions on a given broker results in one or many physical files called segments.
Log
- A log is a data structure that is like a queue of elements.
- A element written at the end of the log and once written are never changed. It is a write once data structure.
- Elements that are written to the log are strictly ordered in time.
Stream
- A stream is a sequence of events.
- A stream is an open ended.
3, A stream is Immutable - A sequence has a beginning and started somewhere in the past. The first event has an offset 0.
- As the stream is open ended we cannot know how much data is coming in the future so, we cannot wait until all the data has arrived to start processing.
- In stream processing one never modifies an existing stream but always generates a new output stream.
Data Element
- A data element in a log is called a record. It is also called as message or event.
- A record consists of Metadata and Body
- Metadata:
- Offset
- Compression
- Magic byte
- Timestamp
- Optional Headers
- Body:
- Key By default determines which partition the message will be written to. Ordering is gaurenteed on the partition and not on a topic.
- Value Contains the Business relanvent data
- Metadata:
Broker
- Producer send messages to brokers
- Brokers receives and stores the message.
- A Kafka cluster will have many brokers.
- Each broker manages multiple partitions.
- A typical cluster has many brokers for high availablility and scalability.
- Each broker handles many partitions for either same topic (If number of partitions are more than brokers) or from different topics.
Broker Replication
- Kafka replicates the partition across broker for fault tolerance.
- Each partition has leader server and 0 or more follower servers.
- Leader servers handles all read and write requests for a partition.
Distribution Consumption
- To increase the throughput in downstream consumption of data flowing in to topic, kafka introduced Consumer Group
- A consumer group consists of 1 or many consumer instances.
- All Consumers in the consumer group are identical clones of each other.
- To add a consumer to the same group, an instance need to use the same group.id
- A consumer group can scale out and paralleize work until
No. of Consumer Instances == No. of Topic partition
ISR In-Sync Replicas
Published on 24 September 2022